Aegina 2019 - Day 1
I recently attended a summer school in Aegina, Greece. It was on the topic of ‘Norms and Biases in Social Interactions’, and organised by Manos Tsakiris and Ophelia Deroy. I covered the non-academic parts of the trip elsewhere, but here I give a rundown of some of the key points made in the lectures.1
Ideas in the lectures were presented at a variety of stages of development, from pre-grant exploration to summaries of years-long research programmes. All of them were presented with confident competence, and typically a sizeable helping of panache.
Keynote
Paul Fletcher’s keynote was the night before the summer school started in earnest, and got the event off to a great start with an ambitious attempt to explain psychosis in predictive processing terms. The most prominent feature of psychosis is a divergence from reality, and this divergence can be explained, at least initially, as a radical attempt to reduce prediction errors by adjusting high-level priors. An example of this process can be seen arising from hallucinations: where hallucinations will generate prediction errors for someone accustomed to the typical behaviour of the world because they are not a feature of the world. Where these hallucinations are persistent, prediction error may be reduced by accepting a shift in the perception of how the world functions.2
{kind=link}
These ideas are supported by some evidence, most compellingly from Mooney images. Mooney images can be recognised once the original image has been seen, but this effect varies and is subject to saturation (if you get shown hundreds of them you can’t remember them all). Recognition is better for some hallucination-prone participants than for controls, suggesting that they retain the priors (provided by the full-colour images) better.
It’s not clear how prediction errors are reduced over a longer time period through the adoption of non-veridical priors (one might suspect that, by definition, delusions cannot be less error-prone than true beliefs), but perhaps delusions provide a non-falsifiable, low-commitment perspective from which sizeable prediction errors are expected: a kind of hedging one’s bets where there’s always some substantial error, but at least high-confidence errors (physiological surprise?) are rare.3
Paul’s talk ended with the suggestion that predictive processing may be decomposable into separate components: low-level bottom-up constraints requiring cognition to accord with the statistical regularities in the world (perhaps designated as predictive coding); which feed into hierarchically organised, context-dependent predictive loops covering progressively longer timescales and more abstract concepts (perhaps designated as predictive processing). Neither of us were sure, in conversations afterwards, how much weight this decomposition might bear, but it will be fun to keep an eye on this work to see how it develops.
Day 1
How should autonomous vehicles drive?
Nadine Fleischhut gave a very well-grounded account of autonomous vehicles, posing the normative question of ‘How should autonomous vehicles drive?’ The answers, as derived from consulting members of the public on trolley problem-like moral dilemmas, which ask whether passenger or pedestrian should be sacrificed in a given scenario, depend rather dramatically on whether the person asked is told they are the passenger (they’re more in favour of sacrificing pedestrians if they’re the passenger).
Nadine’s own work arose in part from general criticisms of moral dilemmas as methods for determining normative policy for autonomous vehicles: the scenarios assume capabilities these vehicles are unlikely to have; certainty which is never available; and equivalence of outcomes which is difficult to justify.4 Nadine’s work presented participants with dilemmas in which the outcomes were probabilistic (decision-making under risk, e.g. an 80% chance a pedestrian in the road will be injured vs. an X% chance a pedestrian on the pavement will be injured if the car swerves), or unknown (decision-making under uncertainty). Results indicated that people had a preference for a simple default: ‘stay in lane and apply the breaks’. This default matches typical human behaviour in similar circumstances. Perhaps the most striking advantage of the simple default strategy is that it is somewhat resistant to hindsight bias: even when there is a bad outcome people are less likely to condemn the decision.
It was interesting to hear that discrimination between people in these kinds of situations is already illegal in some places, which may perhaps be claimed as a victory for the research using moral dilemmas. Abeba Birhane commented afterwards about the inferior detection of black faces exhibited by many of the detection systems in use in current autonomous vehicles, and I wonder whether this inequality constitutes a breech of those same laws. I also wonder whether individual human moral decision-making is the appropriate level at which to treat something as potentially ubiquitous as autonomous vehicles: other policies on a similar scale are typically firmly utilitarian, e.g. allocation of resources in healthcare.
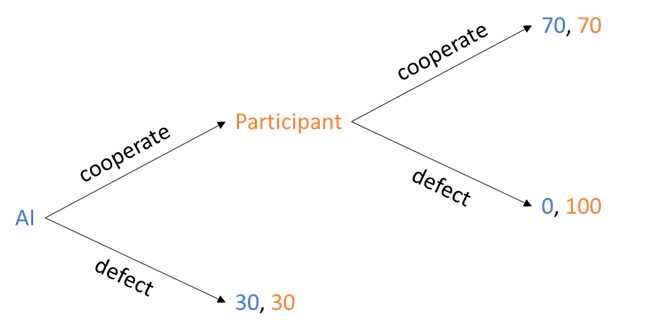
How well do humans cooperate with AI?
{kind=link}
Ophelia Deroy presented work on game theory experiments examining human tendencies to cooperate or defect in interactions with artificial intelligences. By testing participants with a one-shot exposure to payoff structures similar to the one pictured above, Ophelia and her team have demonstrated that humans are more willing to defect on AIs following cooperation than they are to defect on humans. The differences in how humans and AIs are treated is most pronounced where the participants predict cooperation: humans whose cooperation is accurately predicted are cooperated with far more than AIs whose cooperation is predicted. The result replicated impressively in a series of experiments.
People might exhibit this effect, which only appears when there is an opportunity for exploitation (otherwise humans treat humans and AIs similarly), because of algorithm aversion, although this seems tantamount to suggesting that they don’t like AIs because they don’t like AIs. Barry Smith raised the idea of moral patience in the questions, suggesting that humans are more willing to exploit AIs because the AI lacks the aversive conscious experience that humans get when being exploited. I wonder myself whether people are aware that their exploitation contributes to a tragedy of the commons.
Molecular imaging of human emotional systems
Lauri Nummenmaa gave an overview of PET work examining the response of the opioid system to emotional stimuli. Starting with the observation of downregulation of opioid receptors in obese patients (which recovers after bariatric surgery), he presented evidence from a challenge paradigm which indicated that feeing was related to opioid release, while palatability had little effect. Participants offered nutritional drink with a bland taste showed similarly low levels of radioligand to those offered an enjoyable meal, while those supplied with only water showed higher levels.5 The tentative conclusion was that overweight patients increase eating in response to a decreased endogenous reward (more eating is required to earn the same opioid stimulation because of downregulation of receptors).
The logic of the counter-intuitive response whereby a decrease in stimulation increases stimulation-seeking behaviour was illustrated using grooming in monkeys. Opioids are released endogenously when monkeys engage in grooming behaviours. Opioid agonists reduce grooming behaviour because the neurochemical reward has already been achieved (without the necessary expenditure of time or effort). Likewise, opioid antagonists increase grooming behaviour because a reward is expected but not forthcoming. It is not clear at what point long-term blocking of the receptors will lead to a reduction in the behaviour of interest (when the animal eventually learns the behaviour is not rewarding no matter how relentlessly pursued).
Lauri presented work demonstrating that laughter and non-sexual touching produced similar opioid responses in humans. Although PET is the closest we can come in humans to florescence approaches, it has some limitations: for example the difficulties in producing a radioligand which binds to oxytocin receptors and which has the requisite properties of safety, half-life, and ability to penetrate the blood-brain barrier.6 This latter limitation is particularly frustrating given the strong implications for oxytocin’s role in social bonding.
Notes
-
These points are extracted from a combination of my notes and my memory, both of which are at best only noisy indicators of the true content. I imagine a large amount of editorialising is present. If anyone feels their views are misrepresented I’d be happy to include their comments alongside my orthogonal interpretation, so please do correct me! ↩
-
Delusions are often defined as untrue beliefs maintained in the face of sufficient evidence to dispel them, but others have suggested that they are, as the predictive processing account suggests, maintained because of sufficient evidence to support them. This distinction is to do with how thinking works rather than what evidence exists. ↩
-
This last (rather haphazard) suggestion is mine. ↩
-
e.g. the damage caused to a pedestrian by a car is typically much higher than the damage caused to a passenger in a similar-speed collision. ↩
-
PET works by attaching radioactive particles to molecules which bind to receptors for a particular ligand. These radioligands then decay and emit particles which are used to localise the source of the emission. In a challenge paradigm, the endogenous system is engaged (e.g. here by stimulating opioid release through feeding), and then the radioligand is introduced. Where the radioligand cannot bind to a receptor (here because the receptor is already occupied by the endogenous opioid) it is washed out of the system and excreted in urine. In a challenge paradigm, therefore, the less radioligand that is detected the greater the quantity of the body’s own neurotransmitter. ↩
-
I forget who asked this question. ↩